OCR w Linuksie - raport mocno subiektywny (2004 rok)
 Posted on Thu 21 October 2004 in Linux
• [6 min read]
Posted on Thu 21 October 2004 in Linux
• [6 min read]
Pretekstem do napisania niniejszego artykułu było pojawienie się wolnej do niekomercyjnego użytku wersji programu do skanowania Vuescan. Podczas testowania programu okazało się, że funkcja descreeningu czyli usuwania efektu Moire'a, nie działająca we nakładkach do SANE, ani w oryginalnym oprogramowaniu pod Windows, w Vuescanie działa doskonale. Efekt Moire'a ujawnia się najmocniej podczas skanowania druku gazetowego, skanowałem więc właśnie gazety i od ciągłego patrzenia na zadrukowane strony naszła mnie chęć na sprawdzenie jak pod Linuksem działa OCR. Wnioski nie są zachęcające dla osób zainteresowanych dokumentami w języku polskim (i zapewne w pozostałych, innych niż angielski językach). Z rozpoznawaniem tekstu w Linuksie nie jest dobrze, OCR tekstu polskiego jest rzeczą właściwie niewykonalną przy użyciu darmowych narzędzi. Z tekstem angielskim jest lepiej, gorzej za to z jakością i "międzymordziem" programów.
Zacznę od definicji: OCR to z angielskiego optyczne rozpoznawanie znaków (Optical Character Recognition), proces pozwalający przekształcić dowolny czytelny dla człowieka tekst na modyfikowalny format elektroniczny. Mówiąc prościej: program OCR umożliwia nam "wczytanie" dowolnego wydruku (książki, gazety, faksu, itp.) do pliku, co dalej z nim zrobimy to już nasza sprawa.
Akronim OCR przyjął się powszechnie na oznaczenie rozpoznawania tekstu poprzez skanowanie i użycie odpowiednich algorytmów komputerowych do jego rozpoznawania choć z optyką (Optical Recognition) już niewiele ma wspólnego. Bardziej adekwatnym terminem byłby DCR (Digital Character Recognition czyli Cyfrowe Rozpoznawanie Znaków) ale jak w przypadku terminów "hacker" i "cracker" jest już za późno na zmianę. ;-)
Dobry materiał wyjściowy może być skanowany już w rozdzielczości 200dpi, jest to rozdzielczość w której znaki są odpowiednio duże zarówno dla ludzkich oczu jak i dla programu. W praktyce przyjęło się stosowanie rozdzielczości 300dpi i część programów spodziewa się materiału zeskanowanego właśnie w tej rozdzielczości, wyjątkiem jest np. Clara przystosowana przez autorów do 600dpi. Powiększanie rozdzielczości skanowania jest uzasadnione tylko w przypadku bardzo drobnego druku - na przykład liter nie większych niż 6 punktów. Należy pamiętać, że wraz ze wzrostem rozdzielczości nie tylko rośnie wielkość wyjściowego pliku ale powiększa się ilość zbędnych szczegółów, które w najgorszym przypadku mogą zaśmiecić skan i zmniejszyć wydajność procesu OCR.
Drugą, oprócz wielkości tekstu, istotną cechą materiału do OCR-owania jest ilość kolorów. W zasadzie wystarczy zeskanować materiał do pliku w którym na każdy piksel przypada 1-bit (skan czarno-biały) ale czasem dla podniesienia jakości pracy warto zeskanować tekst stosując 256 poziomów szarości (256 greyscale). Część programów życzy sobie jednak tylko czarno-białych skanów (nie posiadają możliwości konwersji do bitmapy) ale nawet w takim przypadku warto zeskanować materiał w skali szarości i przekształcić np. GIMP-em lub convertem (z pakietu ImageMagick) do bitmapy.
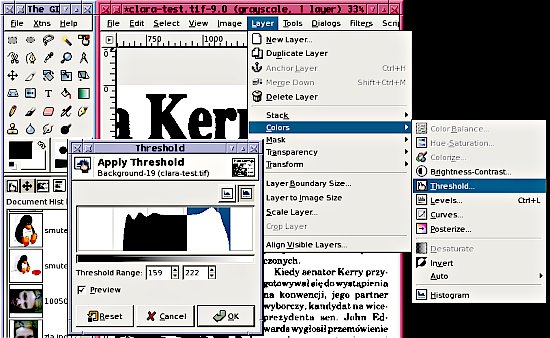
W GIMP-ie 2.0 taką operację przeprowadzam wybierając z menu kolejno opcje: Layers -> Colors -> Threshold (w wersji polskiej: Warstwa -> Kolory -> Progowanie) i reguluję zakres wartości (Threshold Range; po polsku Zakres Progowania) z włączoną opcją podglądu (Preview) aż do uzyskania zadowalającego obrazu. Następnie zapisuję plik w formacie PNM (o formacie opowiadam niżej) co pozwoli mi na jego późniejszą konwersję.
Korzystając z pakietu ImageMagick wystarczy użyć polecenia convert:
convert -monochrome skan.tif skan_mono.tif
lub jego dokładniejszej wersji:
convert -threshold n skan.tif skan_mono.tif
gdzie n oznacza próg jasności piksela powyżej którego piksel zostanie uznany za biały, a poniżej tego progu za czarny. Wartość ta przymuje wartości od 0 do 255 i będzie różna w zależności o jakości skanu nie ma więc innej metody niż kilkukrotne próby z różnymi wartościami do momentu uzyskania dobrego efektu. Tego typu prosta metoda "binaryzacji" obrazu może być przeprowadzona na dwa sposoby. W pierwszym ustawienie progu (threshold) jest globalne dla całego obrazu, w drugiej brane jest pod uwagę sąsiedztwo obrabianych pikseli w, z reguły nierównomiernie nasyconych, obrazach. Niestety nie umiem powiedzieć, którego sposobu używa program convert, może ktoś z czytelników mnie oświeci na forum.
Skanowane materiały zapisuję do plików w formacie TIFF. Format ten, w odróżnieniu od JPEG czy GIF, jest formatem bezstratnym czyli żadna informacja uzyskana ze skanera (z materiału źródłowego) nie zostanie utracona w procesie kompresji obrazu. Niektóre programy OCR przyjmują pliki wejściowe jedynie w formacie PNM. PNM to akronim z angielskiego "Portable aNyMap" (przenośna, dowolna mapa bitowa) odnoszący się do trzech formatów plików graficznych:
- PBM (Portable BitMap) to obraz czarno-biały gdzie na opisanie każdego piksela przypada 1 bit,
- PGM (Protable GrayMap) to z kolei obraz w skali szarości, każdy piksel opisany jest 8 bitami,
- PPM (Portable PixMap) jest obrazem 24-bitowym w pełnej skali kolorów.
Zaletą tego formatu jest możliwość łatwej konwersji np. ze skali szarości do formatu czarno-białego. W przypadku gdy program wymaga pliku graficznego w postaci PBM lub PGM (jak np: Clara OCR) do konwersji można użyć popularnego (i obecnego w większości dystrybucji) pakietu netpbm (http://netpbm.sourceforge.net/). Według podręcznika Clara OCR formaty PBM i PGM nie przechowują informacji o rodzielczości w jakiej skanowany był materiał, warto więc albo zachować oryginalnego TIFFa albo zapisać tę informację.
Mam już gotowe skany, czas na zajęcie się rozpoznawaniem tekstu. Do wyboru mam kilkanaście aplikacji lecz jedynie kilka zasługuje na miano użytecznych. A szkoda, bo najstarsze programy OCR działające w systemach "*nixopodobych" osiągnęły niezłą funkcjonalność już w połowie ostatniego dziesięciolecia XX wieku. Minęło więc ok. 10 lat, a wielkiego postępu w świecie *niksa nie widać. Postanowiłem zbyt wiele nie narzekać ale po prostu zmierzyć się z problemem...
Na cyfrowe rozpoznawanie tekstu składają się trzy fazy: skanowanie, które mam już za sobą, rozpoznawanie znaków i na końcu odczytanie tekstu oraz zapisanie go w postaci gotowej do edycji. Faza druga czyli właściwe OCR to również kilka kolejno następujących po sobie kroków:
- tzw. zoning (strefowanie?) czyli rozpoznawanie poszczególnych elementów strony, odróżnianie tekstu od obrazów, rozpoznawanie tekstu wielokolumnowego, tabel, itp. W tym kroku program OCR może również przeprowadzić automatyczną konwersję obrazu do wspomnianej wyżej 1-pikselowej bitmapy. Tu również możliwe jest użycie funkcji tzw. deskew czyli rozpoznania czy tekst nie został zeskanowany pod kątem i przeprowadzenie ewentualnej korekcji tego błędu. Podczas "zoningu" program określa puste obszary strony - mierzy odstępy pomiędzy poszczególnymi elementami strony i na podstawie ich wielkości decyduje o całym układzie. Niektóre zaawansowane programy (pod Windows np: Omnipage, pod Linuksem Clara lub OCRShop GUI) umożliwiają w tej fazie ręczny wybór obszarów i kolejność ich przetwarzania.
- Kolejny krok to właściwe rozpoznawianie znaków. We współczesnych programach mają zastosowanie algorytmy sieci neuronowej, pozwalające na analizę kształtów i kwalifikowanie ich jako poszczególnych znaków. Pierwsze systemy OCR, mające zastosowanie między innymi przy sortowaniu poczty (USA lata 60-te) umiały jedynie rozpoznawać, wcześniej określone rodzaje czcionek (właściwie tylko dwa rodzaje: Courier oraz czcionka o nazwie OCR A). Algorytm kwalifikujący porównywał kształt znaku zeskanowanego z przygotowanymi wcześniej tablicami znaków. Były to bazy danych, przechowujące w postaci bitmap kształty poszczególnych czcionek. Rozpoznawanie tekstu odręcznego lub napisanego nieznaną czcionką dawało mizerne rezultaty. Dopiero zastosowanie przez Raymonda Kurzweila w 1976 roku (http://www.ccs.neu.edu/home/elan/ray.html) algorytmów sztucznej inteligencji pozwoliło na polepszenie jakości procesu OCR i rozpoznawanie już nie tylko różnych kształtów czcionek ale i różnych zestawów znaków.
- Następny krok to rozpoznawanie słów. Rozpoznane ciągi znaków mogą być porównywane są z słownikami .
- Korekta. Efekt dotychczasowych wisiłków zachowywany jest w formacie umożliwiającym odtworzenie pracy, jest to z reguły format pliku specyficzny dla danego programu. W tej fazie niektóre programy przełączają się w tryb interaktywny podczas którego użytkownikowi prezentowane są "podejrzane", nierozpoznane znaki. Użytkownik decyduje, ktore znaki są prawidłowe, a które wymagają korekty. Podczas tej fazy program zapamiętuje właściwe wybory i na ich podstawie może automatycznie skorygować resztę tesktu.
- Zapisanie tekstu w wybranym formacie umożliwiającym późniejszą obróbkę.
W porównaniu programów zajmę się przedewszystkim rezultem działania OCR. Dodatkowe funkcje jak "binaryzacja" obrazu czy deskewing (prostowanie) to miłe udogodnienia, można jednak zastąpić je użyciem zewnętrznych narzędzi. Z tego względu jedynie wspomnę o tych funkcjach jeżeli testowany program je posiada.
Ponieważ niektóre programy w ogóle nie obsługują jezyków innych poza angielskim, do testów użyłem zarówno tekstu polskiego jak i angielskiego - po prostu chcę wiedzieć ile jest wart algorytm OCR danej aplikacji.
Druga część raportu już niedługo. Zapraszam.