Skrypt kontra Spamerzy
 Posted on Wed 06 May 2020 in Administracja
• [6 min read]
Posted on Wed 06 May 2020 in Administracja
• [6 min read]
Walka prawie jak w japońskim filmie "Godzilla kontra Mechagodzilla". Na pierwszy rzut oka wydaje się, że tytuł mi niezbyt wyszedł, bo w tytule pierwsze jest żywe zwierzę bijące się z mechanicznym potworem z kosmosu, ale przecież za skryptem stoi żywy człowiek, ja, mierzący się z automatami zwanymi botami. Analogia jest więc bezpośrednia.
Od kilkunastu godzin na jednym z serwerów mailowych, którymi zarządzam, trwa atak botów na Postfiksa. Mechanizmem obronnym serwera jest rspamd, który spisuje się bardzo dobrze ale mnie wkurza ilość logów jak przy tym powstaje. Włączam tail -f i ekran przypomina sieczkę z holyłódzkich produkcji. Przykładowa linia z pliku logu, ilustrująca toczącą się potyczkę, wygląda następująco:
May 4 17:06:37 fubar postfix/submission/smtpd[20510]: warning: hostname client.yota.ru does not resolve to address 188.162.199.161: Name or service not known
Widać tu próbę podszycia się pod inny adres, zachowanie bardzo charakterystyczne dla spammerów.
Podobnych linii zebrało się już kilkadziesiąt tysięcy i w końcu postanowiłem coś z tym zrobić. Szybko wpadłem na pomysł blokowania Mechagodzilli za pomocą firewalla czyli linuksowych iptables.
Postanowiłem sworzyć blacklisty adresów IP za pomocą narzędzia ipset. Najprostszy sposób wykorzystania ipseta opisany jest np. na tej witrynie.
No dobrze, ale jak skonstruować listę? Inaczej, jak zebrać adresy spammerów i jak zdecydować czy na pewno to spammerzy?
Wystarczy 1-linijkowiec, który wygląda tak:
grep 'does not resolve to address' /var/log/mail.info | cut -d " " -f15 | sed -e 's/://' | awk '{ count[$0]++ } END {printf("%-20s%s\n","IP Address","Count") ; for(ip in count) { printf("%-20s,%d\n",ip,count[ip]); }}' | sort -g -t, -k2
Tylko z pozoru jest skomplikowany, gdy wytłumaczyć co tu się dzieje stanie się prościutki, ale w tym celu muszę go rozbić na kawałki.
Pierwsza część:
grep 'does not resolve to address' /var/log/mail.info
znajduje wszystkie linie zawierające ciąg 'does not resolve to address' w logu. Komenda grep robi to co najczęściej robi kura... grzebie. W tym przypadku grzebie w pliku mail.info w poszukiwaniu podanego ciągu znaków. Efektem tej komendy jest taka lista:
May 4 17:06:37 fubar postfix/submission/smtpd[20510]: warning: hostname client.yota.ru does not resolve to address 188.162.199.161: Name or service not known
May 4 17:14:43 fubar postfix/submission/smtpd[20670]: warning: hostname 29.3.dialup.mari-el.ru does not resolve to address 77.40.3.29: Name or service not known
May 4 17:14:53 fubar postfix/submission/smtpd[20670]: warning: hostname 29.3.dialup.mari-el.ru does not resolve to address 77.40.3.29: Name or service not known
May 4 17:14:58 fubar postfix/submission/smtpd[20684]: warning: hostname 7.62.pppoe.mari-el.ru does not resolve to address 77.40.62.7: Name or service not known
I tak dalej, i tak dalej... dziesiątkami tysięcy.
Następna część 1-linijkowca korzysta z narzędzia cut, które jak sama nazwa wskazuje wycina pewne fragmenty przekazanego mu tekstu:
cut -d " " -f15

Parametr -d " " to ogranicznik czy może w tym przypadku rozdzielacz, może separator, czyli znak, który oddziela od siebie poszczególne pola. Tu jest nim spacja. cut dzieli tekst na pola w miejsach gdzie pojawia się spacja, a parametr -f15 mówi mu, że ma się skupić wyłącznie na polu o numerze 15, licząc od lewej. Efekt działania tej części wygląda już dość interesująco:
51.75.170.188:
51.75.170.188:
77.40.62.101:
81.62.210.170
77.40.3.29:
77.40.3.29:
77.40.62.7:
77.40.3.79:
77.40.62.7:
51.75.170.188:
162.243.143.209
14.140.150.186
202.43.160.219:
188.162.199.206:
188.162.199.189:
51.75.170.188:
bo są to upragnione adresy IP (chyba) spammerów.
Teraz następuje mała kosmetyka bo, jak widać powyżej, nie wszystkie adresy wyglądają tak samo. Większość kończy się znakiem dwukropka ale niektóre nie. Trzeba jest zserializować czyli ujednolicić. Do tego służy sekcja z narzędziem sed:
sed -e 's/://'
Parametr -e daje znać sedowi, że to co jest po jego prawej stronie to komendą, którą musi zinterpretować i wykonać na przekazanym mu tekście (czuję, że się powtarzam...). Komendę s/:// należy odczytać: "zamień wszystkie dwukropki na nic" albo "usuń wszystkie dwukropki". Efektu nie pokazuję bo jest to lista j.w. tyle, że pozbawiona "kolona".
Z tym dwukropkiem czyli po angielsku "colon" jest dość śmieszna sprawa, bo jakby się nie natężać, nie można pominąć jego odbytniczego znaczenia. Nie miałem kolonoskopii ale gdy tylko dowiedziałem się jak Anglicy wymawiają dwukropek skojarzenie wyskoczyło automatycznie. Nie tylko ja mam ten problem, oto dwa fragmenty tłumaczenia tej samej definicji "kolona" wziętej z Wikipedii.
Pierwszy wykonany guglowym translatorem:
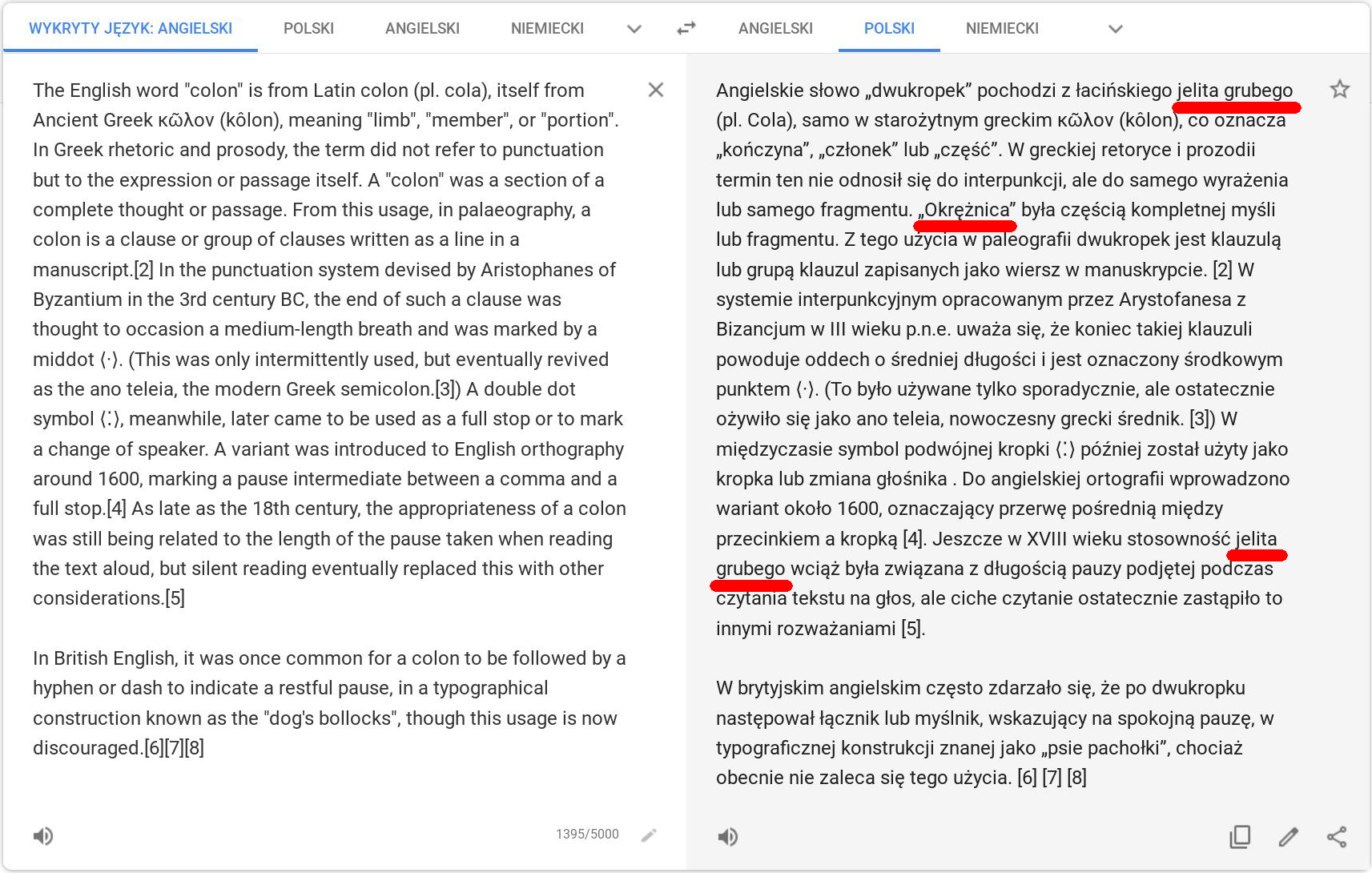
Drugi niemieckim, sztucznie inteligentnym DeepL-em:
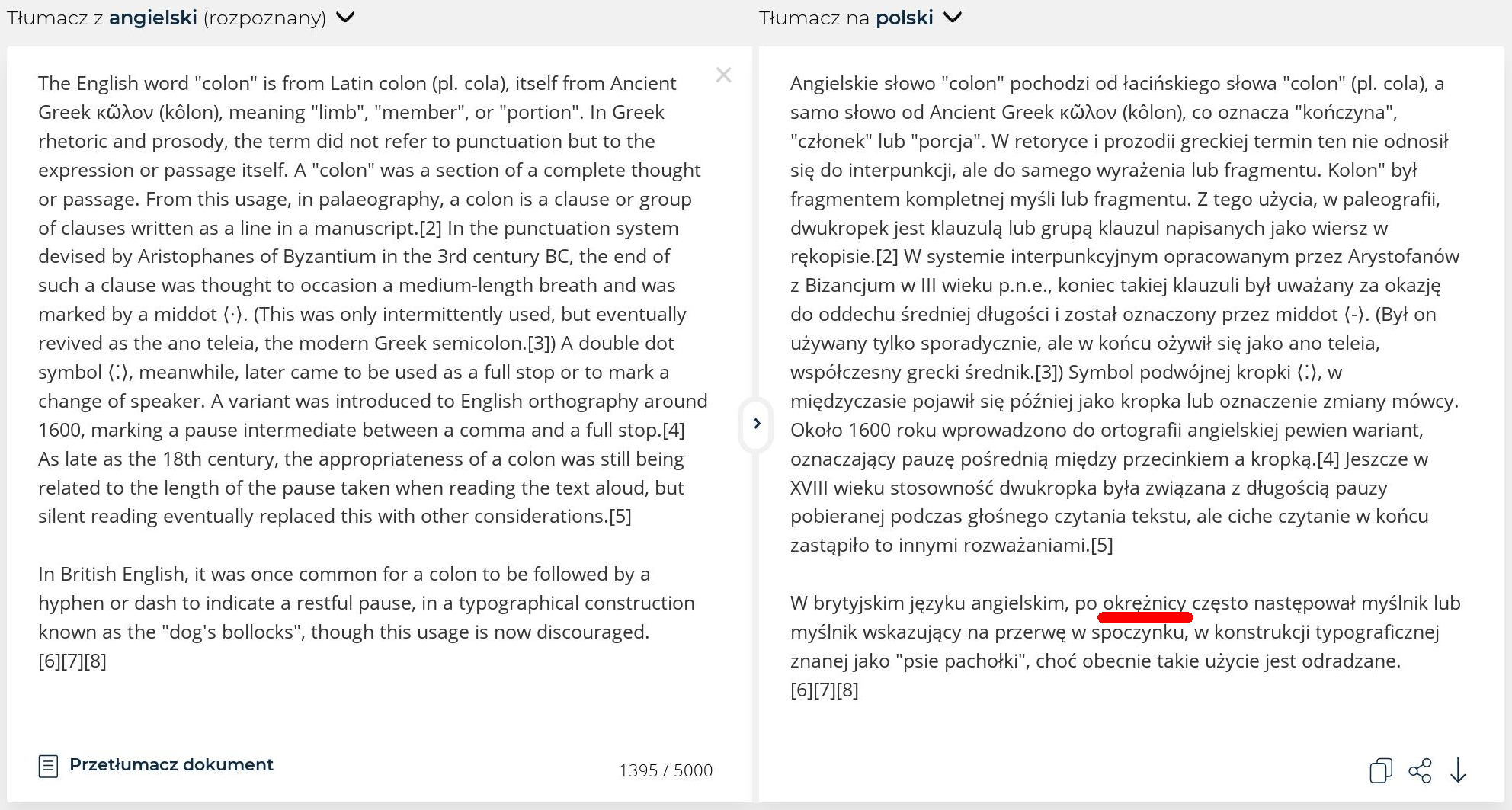
Kto wygrał pojedynek na tłumaczenia pozostawiam do rozstrzygnięcia Szanownemu Czytelnikowi i... szczerze polecam zapoznanie się z historią dwukropka:

Po tej skromnej dygresji, wracam do sedna czyli przedostatniej części 1-linijkowca. Tu pojawia się kolejne narzędzie: wszechmocny AWK:
awk '{ count[$0]++ } END {printf("%-20s%s\n","IP Address","Count") ; for(ip in count) { printf("%-20s,%d\n",ip,count[ip]); }}'
Pierwszym fragmentem , którego działanie wytłumaczę jest { count[$0]++ }. Awk operuje na rekordach i polach, zwykle podaje się znaki będące separatorami rekordów i pól lecz gdy nie są one podane, separatorem pól staje się znak nowej linii. To co trafia do awka w moim przypadku to lista adresów IP, każdy oddzielony nową linią, zatem każdy z nich staje oddzielnym rekordem. Wyrażenie count[] to tablica, do której zbierane są liczby wystąpień danego adresu IP i, co najpiękniejsze, indeksy tych liczb są samymi numerami.
Może wyjaśnię to przez analogię do parkingowego, któremu zlecono policzenie ile samochodów danej marki stoi aktualnie na placu. Facet bierze w ręce zeszyt oraz ołówek i rusza na przechadzkę. Napotyka Fiata, więc zapisuje w kajecie "Fiat", a obok wpisuje jedynkę. Idzie dalej i natyka się na Forda, analogicznie pisze "Ford" i obok stawia jeden. Idzie dalej, znowu Fiat, więc przy "Fiacie" zmazuje gumką 1, i w jej miejsce wpisuje 2.
I tak dalej. Na koniec obchodu ma tablicę marek wraz z liczbami stojących aut. Zapytany ile jest Fordów, wyszukuje w liście słowa "Ford" i widzi, że obok jest 13. Cholera... a raczej: Korona... pechowa liczba!
Wracam do skryptu. Gdy awk napotyka rekord, tu przedstawiony w postaci $0, czyli adres IP, wrzuca go do tablicy count[] i pod jego indeksem zapisuje jedynkę. Ale uwaga! Ponieważ na końcu tablicy są dwa plusy, które oznaczają inkrementację o 1, to gdy awk napotka adres IP znajdujący się już w tablicy, zrobi to samo co parkingowy - zmaże 1 i postawi 2. I tak dalej.
Wracając na chwilę do parkingowego... jego obchód wyglądałby tak:
{ auta[marka]++ }
Gdy pierwszy segment programu awka kończy swoje działanie można sobie wyobrazić, że dostajemy coś w tym stylu:

Następnym segmentem skryptu awka jest słowo END. To sygnał, że gdy pierwszy segment zakończy działanie, należy wykonać to co jest po prawej stronie END, a jest to:
{printf("%-20s%s\n","IP Address","Count") ; for(ip in count) { printf("%-20s,%d\n",ip,count[ip]); }}'
To są dwa oddzielne zadania, widać to po użytym, rozdzielającym je, średniku. Pierwsze ma znaczenie wyłącznie kosmetyczne i bez kłopotu może być całkowicie usunięte ze skryptu.
{printf("%-20s%s\n","IP Address","Count")
for(ip in count) { printf("%-20s,%d\n",ip,count[ip]); }}'
To jest pętla for, którą w języku polskim opisuje się słowami "dla każdego...". W powyższym przypadku będzie to zatem "dla każdego ip w tablicy count". W nawiasie klamrowym są polecenia co ma się dziać dla każdego ip z tablicy count, a ma to być ponownie proces drukowania (wyświetlania) na ekranie. I znowu, jak powyżej, są to dwie frazy - pierwszą jest ip czyli indeks elementu tablicy, jak pisałem wcześniej jest to po prostu adres IP. Drugą frazą jest liczba wystąpień tego adresu, otrzymuje się ją podając nazwę tablicy z indeksem: count[ip].
Efektem pracy tego segmentu skryptu jest następujący spis (oczywiście tutaj tylko początkowy fragment):
IP Address Count
77.40.61.241 ,1
188.162.199.215 ,6933
52.100.18.18 ,1
52.100.19.71 ,1
188.162.199.9 ,31
188.162.43.144 ,2819
52.100.19.72 ,1
52.100.19.59 ,1
188.162.199.231 ,2387
188.162.199.198 ,38806
188.162.43.145 ,528
52.100.19.73 ,1
52.100.18.34 ,2
188.162.199.199 ,2027
77.40.61.245 ,1148
188.162.199.232 ,43
52.100.19.74 ,2
188.162.43.160 ,1500
Jak widać, w lewej kolumnie są adresy IP, w prawej zaś liczby wystąpień.
Czas je posortować by wybrać te, które występują najczęściej. Im częstsze wystąpienie tym większe prawdopodobieństwo, że jest adres IP jest częścią jakiegoś niecnego botnetu.
Naturalnie ważną kwestią jest zakres czasowy w jakim zostały zgromadzone dane. W moim przypadku są to godziny. Gdyby chodziło o lata, należałoby wziąć pod uwagę, że "legitne" (to słowo ze slangu moich synów oznaczającego coś uczciwego) serwery mogłyby zostać uznane za zbyt często nawiązujące połączenie.
Sortowanie jest trywialne dzięki przecinkowi, który rodziela kolumny:
sort -g -t, -k2
Parametr -g programu sort włącza sortowanie numeryczne, fakt rozdzielenia kolumn za pomocą przecinka wykrywa parametr -t,. I ostatni parametr -k2 mówi, że sortujemy po kolumnie numer 2 czyli tej z prawej, po przecinku. Litera "k" w parametrze tak naprawdę nie oznacza kolumny, bo w j. angielskim byłoby "c", jest to po prostu pierwsza litera słowa "key" ale akurat w polskim wszystko "zostaje w rodzinie".
Przy okazji wyszło na jaw, że nomenklatura w Linuksie, czy szerzej w *niksach, nie jest ujednolicona, i to co gdzieś jest indeksem, gdzie indziej może być polem. Z tego faktu mieli niezły ubaw hackerzy m. in. takich systemów jak VMS, a swoje przemyślenia zawarli w prześmiesznej (dla nerda) książce "The Unix Haters Handbook". Polecam.

Zrobiło się późno ale pisało mi się to bardzo przyjemnie. Jutro, jeśli będzie czas, napiszę dalszą część przygody ze spammerami czyli jak otrzymane dane zastosować do aktywnego ich blokowania.
Buenas Noches!
p.s. Tak wiem, że jest fail2ban ale lubię czasem zbudować płot własnoręcznie.